Panda Podcasting

Spent the day setting up another set of services on the Pandabox, my small NUC form-factor server that I use to self-host as many services as possible to wean myself off of algorithmically-maintained subscription services. Today's project was "podcasting".
I don't really listen to that many typical podcasts. Many of them seem based on "chatter" and I'm not the biggest fan of listening to multiple voices talking into my ear; I prefer narratives, with a single voice talking and maybe additional guest voices here and there similar to a TV documentary. I think it's an attention thing - if it's one voice talking in a similar tone, using the cadence of a storyteller I can be lulled into a sense of relaxation, where my brain builds images and follows along with the narration while my attention is focused on what I'm working on actively. If it's multiple voices, that's harder for me to do.
Man, when ADHD superpowers got handed out, I got the worst.
Anyway, a lot of the time, I end up listening to long-form Youtube content, usually history or tech (and tech history) documentaries, but relying on Youtube presents me with a few problems.
I don't like being reliant on a webpage/app. I previously solved this by using a nifty emacs package called yeetube which causes emacs to act as a front-end for yt-dlp, a command-line youtube downloader that could be set to convert youtube videos to audio-only tracks on the fly. I could listen to youtube videos in God's Own Chosen Text Editor but that left me tethered to my laptop. As much as I hate smartphones, it's hard to argue with the convenience of being able to drop your phone in your pocket and keep walking. This, however, introduces the problem of having to run the youtube app on my phone and thus eating up my battery to display the video content I wasn't using.

I already use audiobookshelf as a self-hosted audiobook service and I know that it also supports podcasting. There had to be some way to use it (and leverage its features, like progress tracking across multiple clients) in listening to Youtube 'podcasts'.
There's an enormous ecosystem of programs and tools based around what /r/datahoarder so gently calls "Youtube archiving". I'm not ashamed to admit that I have a few data hoarder tendencies (ask me how many ROMs and game ISOs I have on my NAS that I'm probably not going to play….) and I've always kind of been interested in the idea of incorporating select Youtube channels into my Jellyfin media setup as I watch some of them as much as, if not more than, some actual television shows. I've never pulled the trigger on it because, well, storage is expensive.
But I have amassed some of those tools and thought about how I could put that knowledge to use to address my current problem.
Enter Pinchflat
Pinchflat is a Docker application that is meant for archiving Youtube channels. It's designed around incorporating Youtube content into your media server (Plex, Jellyfin, etc). It does its best to embed metadata taken from the video's page into the file in a format that those tools can ingest easily. It uses yt-dlp and ffmpeg as its core.
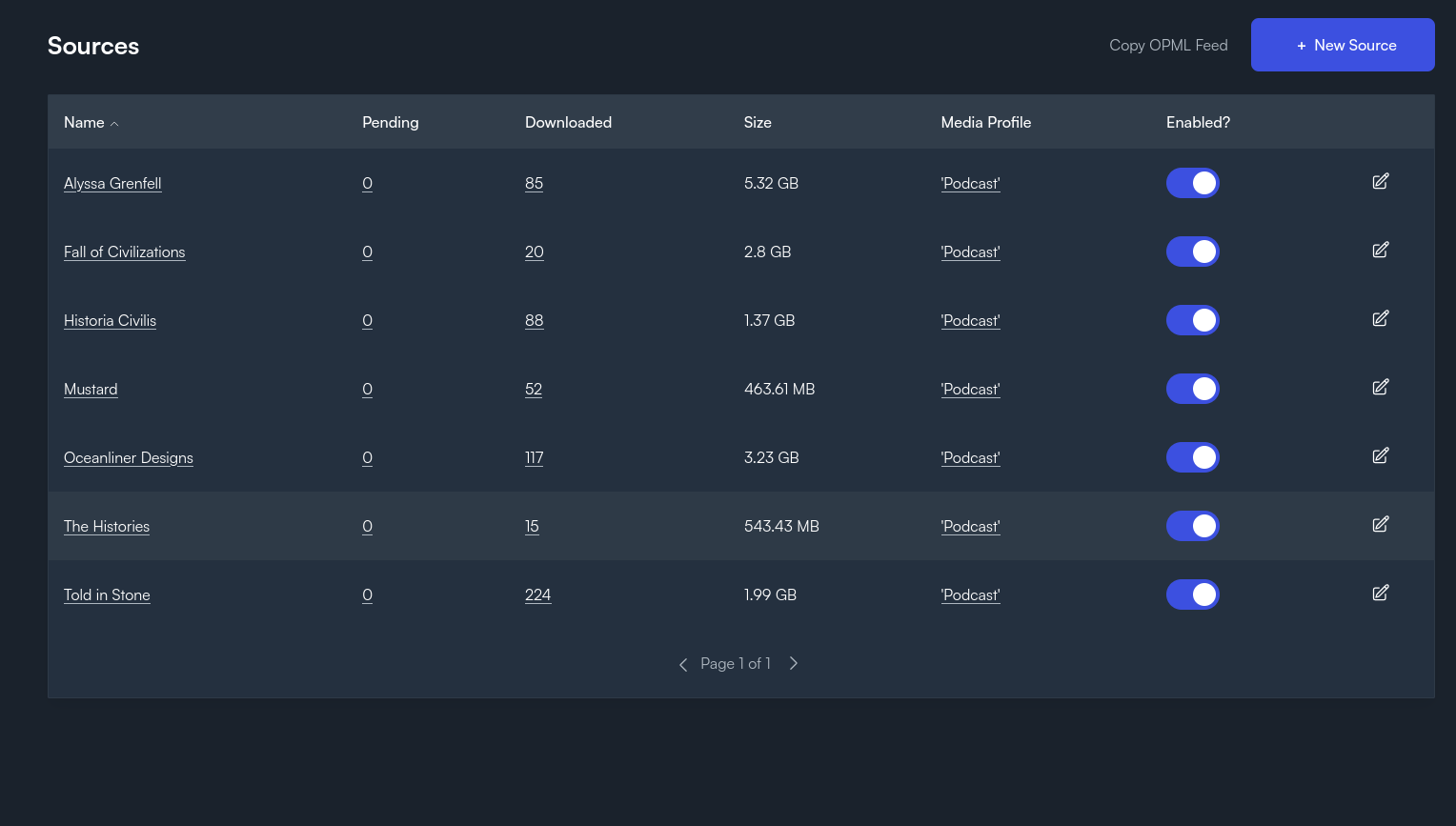
Pinchflat relies on two components: a media profile and a source. Sources are the content that you want to download; these can be whole channels or playlists. The program isn't really well designed to be able to grab and download single, individual videos however the creator does suggest simply adding the video in question to an unlisted playlist and then adding that as a Media Source. You can try and restrict certain types of content; Pinchflat has a kind of fuzzy logic way of telling whether or not a video is a genuine Youtube video or a Youtube Short and it seems fairly good at ignoring the latter if you tell it to.
Pinchflat will also check the Sources that you give it for new content on a daily (or weekly or monthly or whatever you set) basis. It also has Sponsorblock integration and can be told to delay grabbing a new video to wait for Sponsorblock segments to hit the DB.
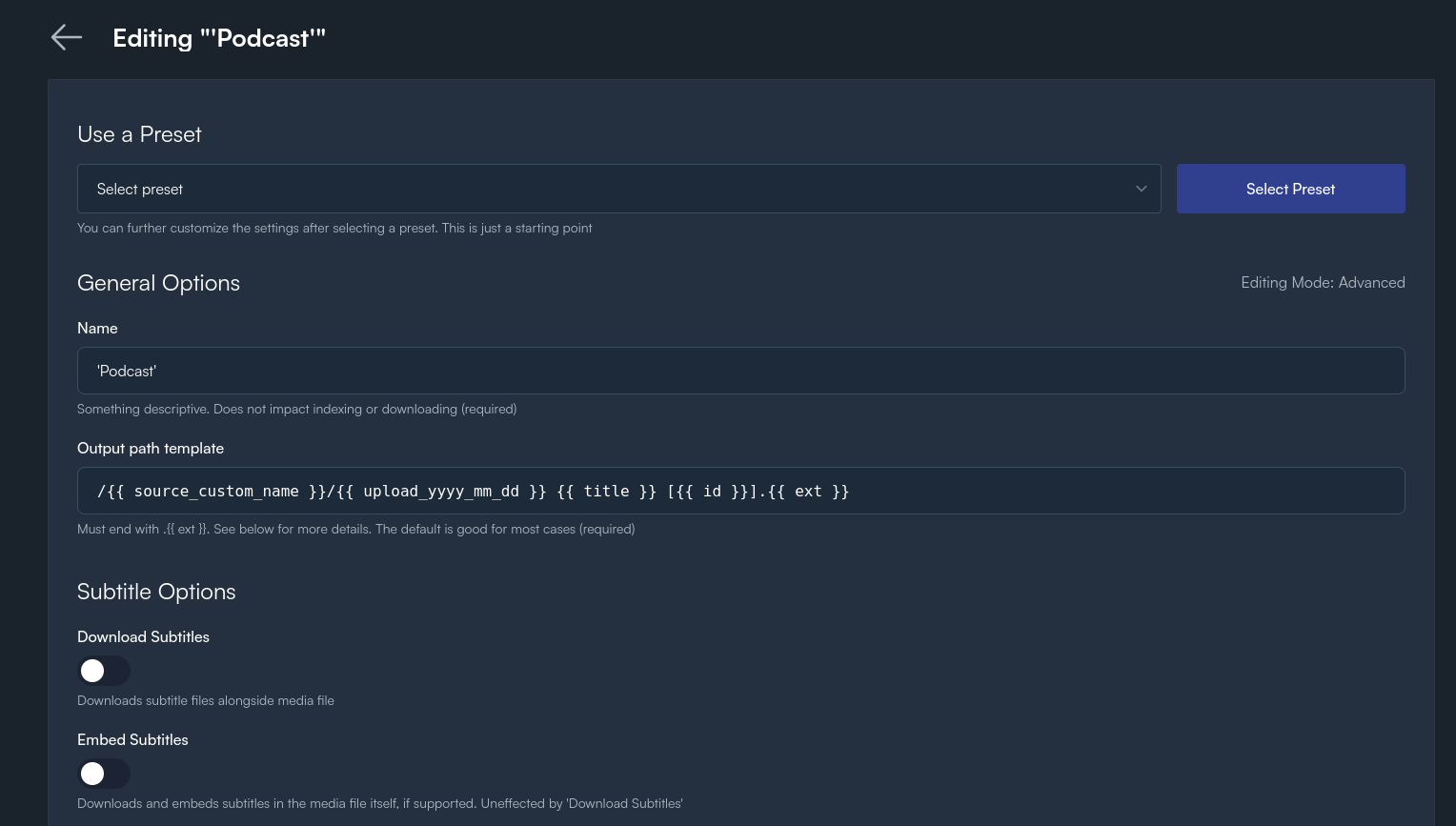
The next thing you need to create is a Media Profile and that dictates how you want the media to be downloaded (things such as output format, output filenames, metadata, quality, and the like). I've created one called 'Podcasts' that downloads the Youtube video and then extracts the audio stream, converts it to m4a, and dumps it into a folder that my audiobookshelf docker can access it.
Finally, in audiobookshelf, create a Podcast Library (or add the Pinchflat output folder to your current one) and audiobookshelf will import them as Pinchflat downloads them.
Please note the output path name template in the Media Profile image: Pinchflat really seems designed around the expectation that you would grab these videos as, well, videos, and import them into Jellyfin/Plex/et al so it has a lot of rules about how to create metadata for media servers to ingest. Audiobookshelf is….less smart about picking up on a lot of those things. By default, Pinchflat seems to want to put each downloaded video into its own folder (assuming that each video is an episode of a show) which Audiobookshelf will then interpret as a distinct, single-episode, podcast. Using the string in the image above will label each download with its name and publication date and then put each of them into a folder named with the channel or playlist that it came from (it's this folder that Audiobookshelf will derive the name of the 'podcast' from, thus correctly adding the audio files as episodes of a single podcast). Doing it that way will ensure that each audio file is picked up as an 'episode' in that 'podcast'.
And…that's pretty much it. Add your sources, create your media profile and wait for Pinchflat to do its thing.